本文共 4359 字,大约阅读时间需要 14 分钟。
本博客主要是台湾大学-李宏毅老师的公开课的总结()。
一、简介
迁移学习主要是指将已有数据的领域知识迁移到数据缺乏的领域任务中,下面简单介绍下:
-
出现原因
迁移学习主要用于将源域(source domain)的知识迁移到目标域(target domain),也可以理解为源域的数据辅助目标域数据的决策。其出现的主要原因是目标域数据较少,若仅仅使用目标域的数据,不足以训练一个比较好的模型,所以我们借助源域的数据,提高目标域上的任务性能。(源域和目标域可能子任务不同,但是其数据还是有一些共性)。 -
举例
比如你现在希望训练台语的语音识别任务(目标域:台语),台语的数据量比较小。我们可以其他语音(英语、中文等)的数据来提高台语的语音辨识任务。
二、Overview
| Source Data(not directly related to the task) | |||
| labelled | unlabelled | ||
| Target Data | labelled | Model Fine-tuning Multitask Learning | Self-taught learning |
| unlabelled | Domain-adversarial training Zero-shot learning | Self-taught Clustering | |
关于迁移学习的方法如上表所示,这里主要介绍当source data是labelled的情况。
三、Model Fine-tuning
Model Fine-tuning适用于目标域数据很少,源域数据比较多的情况。(注意:在Model Fine-tuning中,目标域数量较少,但是若目标域数据量少到只有几个的时候,这时候叫做one-shot learning)。
1、举例
仍然是语音识别来辨别某一个人的声音,目标域数量比较少,比如是某一个人的语音数据;源域数量比较多,可以是很多人的数据。
2、方法
可以使用source data训练模型,然后在target data中使用之前的模型和参数并微调参数。
但是这样做可能会有问题,即若sourde data和targt data的数据相差太大,即使是在source data上训练很好的模型,在target data上也不一定起作用。这时候便需要一些特殊的技巧:
- Conservative Training 在进行微调的时候,目标函数可以增加条件使得source data上的模型和target data上的模型相差不是太大。
- Layer Transfer i) 可以只调节某一层,即拷贝其他层的参数,保留一层或少量几层进行训练。这样训练的参数会比较少 ii) 当数据量逐渐增多的时候,可以在进行模型参数的微调。 那么,这就涉及到一个问题,我们在拷贝的时候需要拷贝哪几层的参数呢?针对这个问题,可能需要分析具体的场景,下面是李宏毅老师给出的例子。 ①在语音识别任务中,一个人的口腔结构、发音特点等不同,前几层不同人的特征相差较大。而后面几层,挖掘的可能是语言本身的特点,不同的人有很多共性,所以对于语音识别的任务,我们就可以优先对前几层的参数进行调整。 ②在图片识别任务中,前几层网络识别的可能是一些基本的图片pattern,比如图片轮廓、边角等,对于这些pattern来说,猫、狗、猪啊这些挖掘方法都比较类似,而后几层可能是更深入得挖掘与图片识别结果更相关的特征。所以对于图片识别任务来说,我们一般对网络的后几层参数进行调节,而保持前面几层的网络参数不变。
四、Multi-task Learning
多任务学习是指如有多个相似的任务,则他们可以共享网络的某几层,如下图所示:
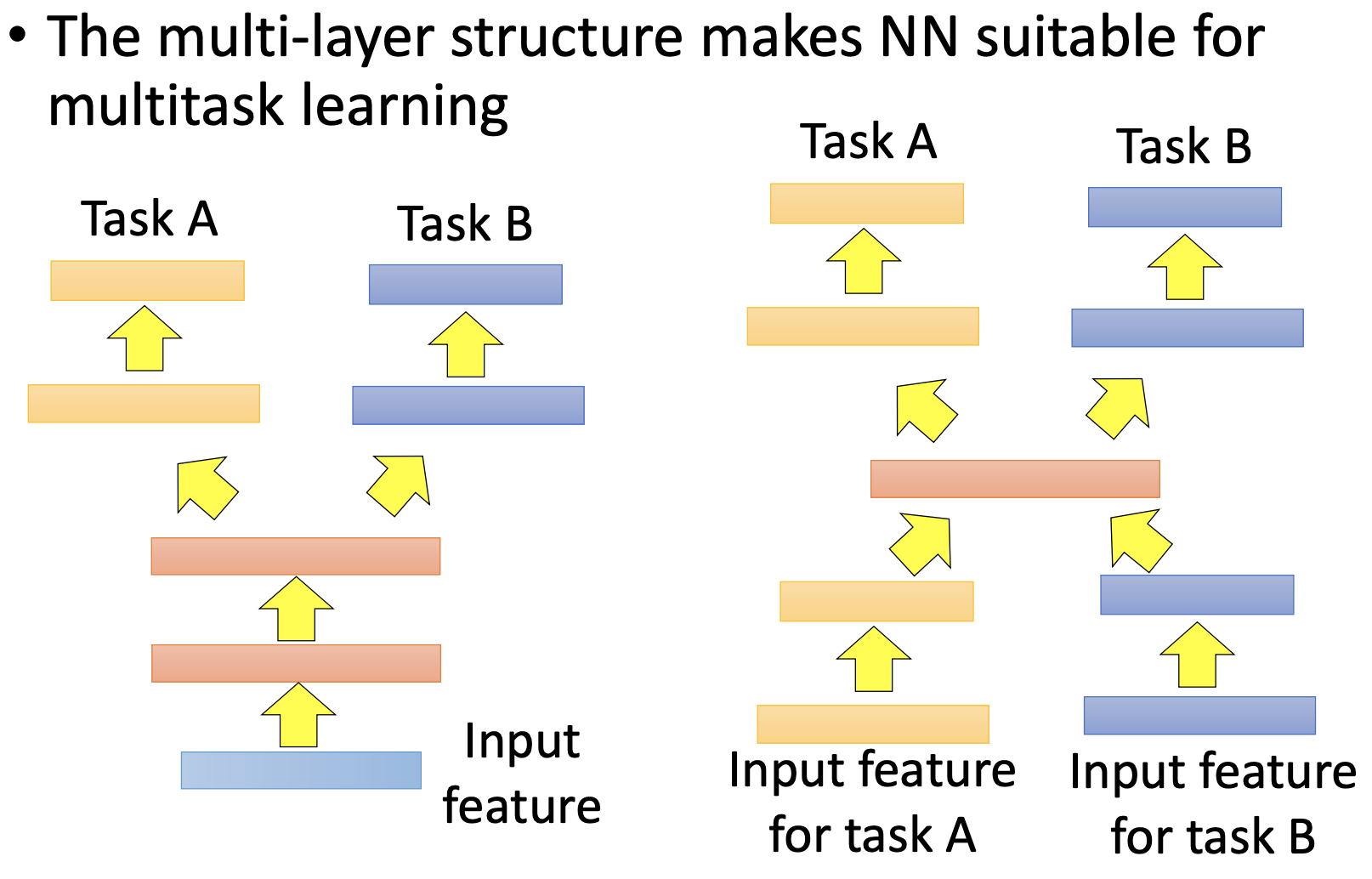
左图所示部分是task A和task B共享前几层的神经网络,只是在最后几层的时候区分task A和task B。右图部分是开始几层和最后几层都不共享,只分享中间少数层。
还有另一种progressive的训练方式,如下图所示,在progressive的任务中,Task 2中一部分task 1中的参数,task3借助task1和task2中的参数:
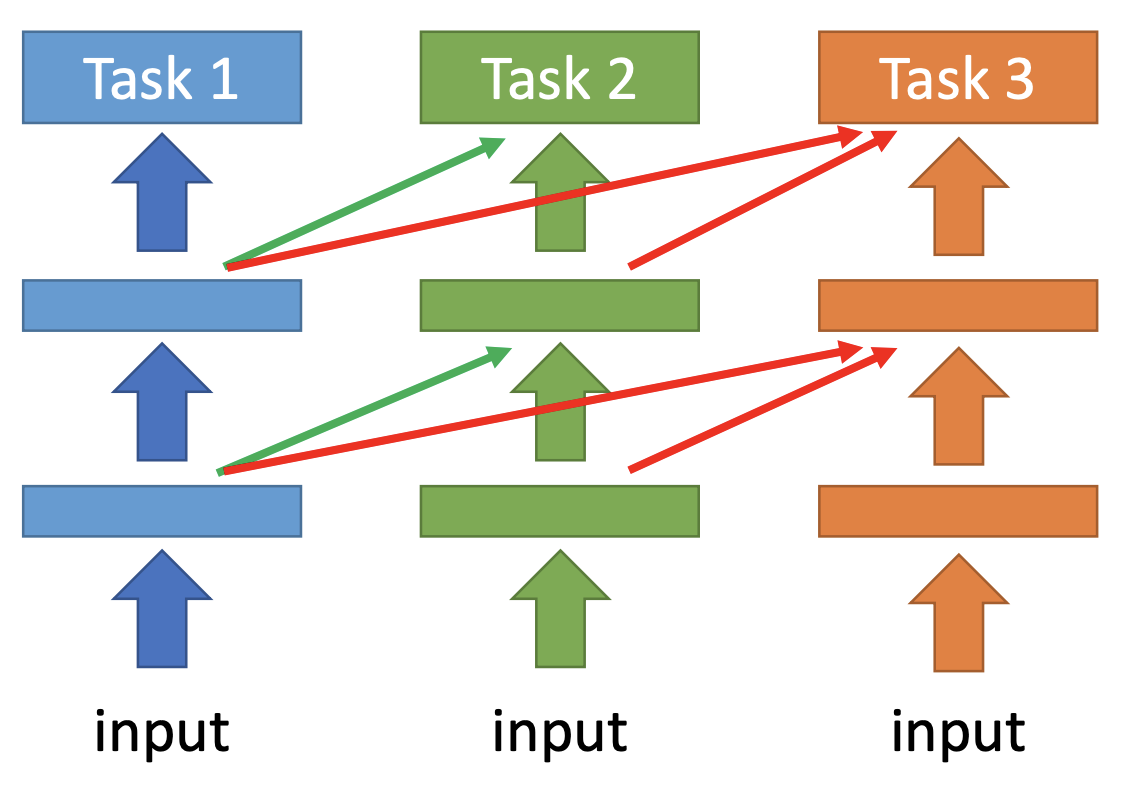
前面的multi-task的方法中task A和task B是相互影响的,而在这种multi-task的任务中,task1不受后续操作的影响。
五、Domain-adversarial training
Domain-adversarial training主要针对source data是有labelled,而target data是没有labelled的情况。下面是一个例子:

上图所示,我们的source data和target data虽然都是数字识别的任务,但是source data是黑色底色的,而target data是有彩色背景的。如果把source data的模型迁移到target data中,我们可以想象出来可能出现的问题便是source data无法识别出彩色背景,或者直接将彩色背景加入到数字的特征中,下面是source data和target data的降维展示结果,其中蓝色的表示0-9的数字,可以看出,不同的数字还是明显分成多个团子的,而红色的表示彩色背景的,也就是说彩色背景的数字完全没有被区分开来:
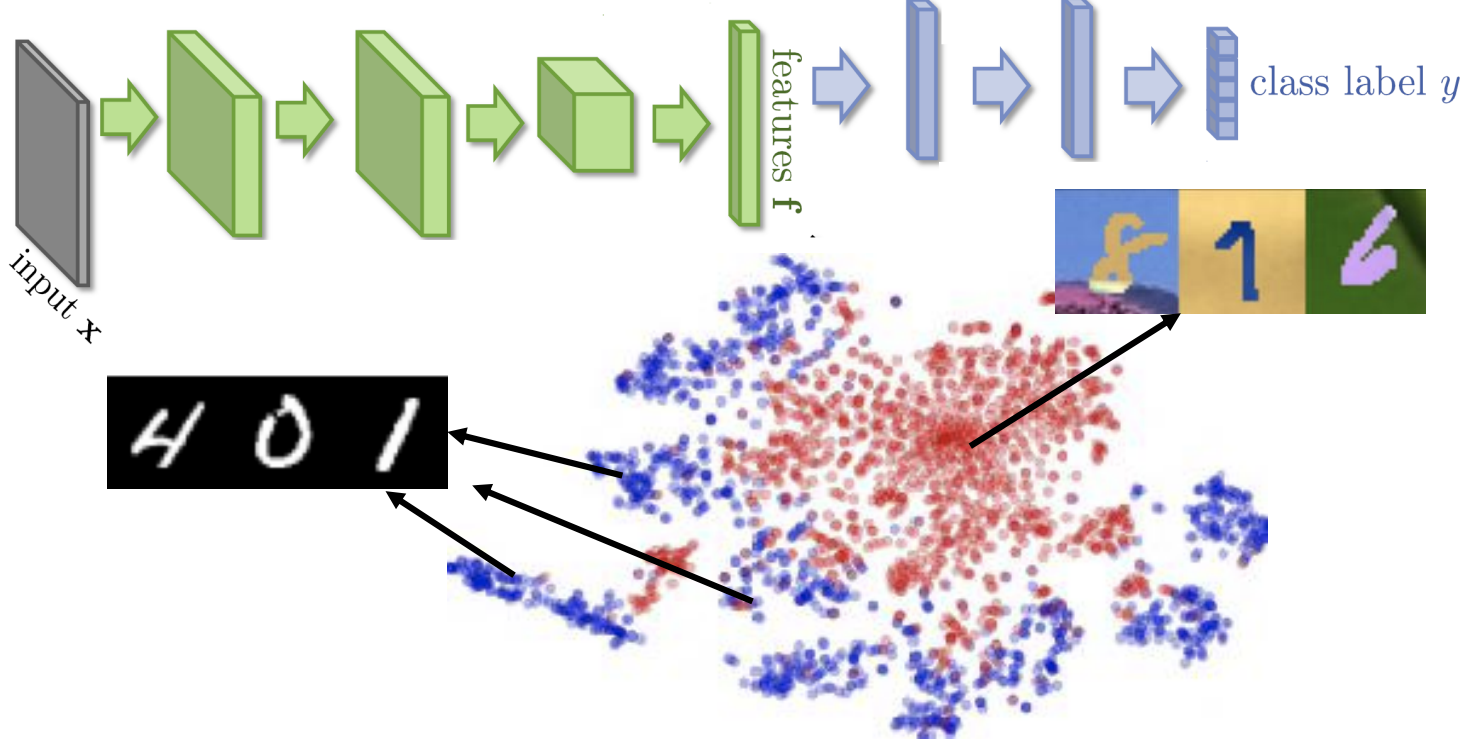
上面的例子说明,如果我们直接将source data的模型迁移到target data中,则并不能很好地表示target data的信息。
那么domain-adversarial training是如何解决的呢?
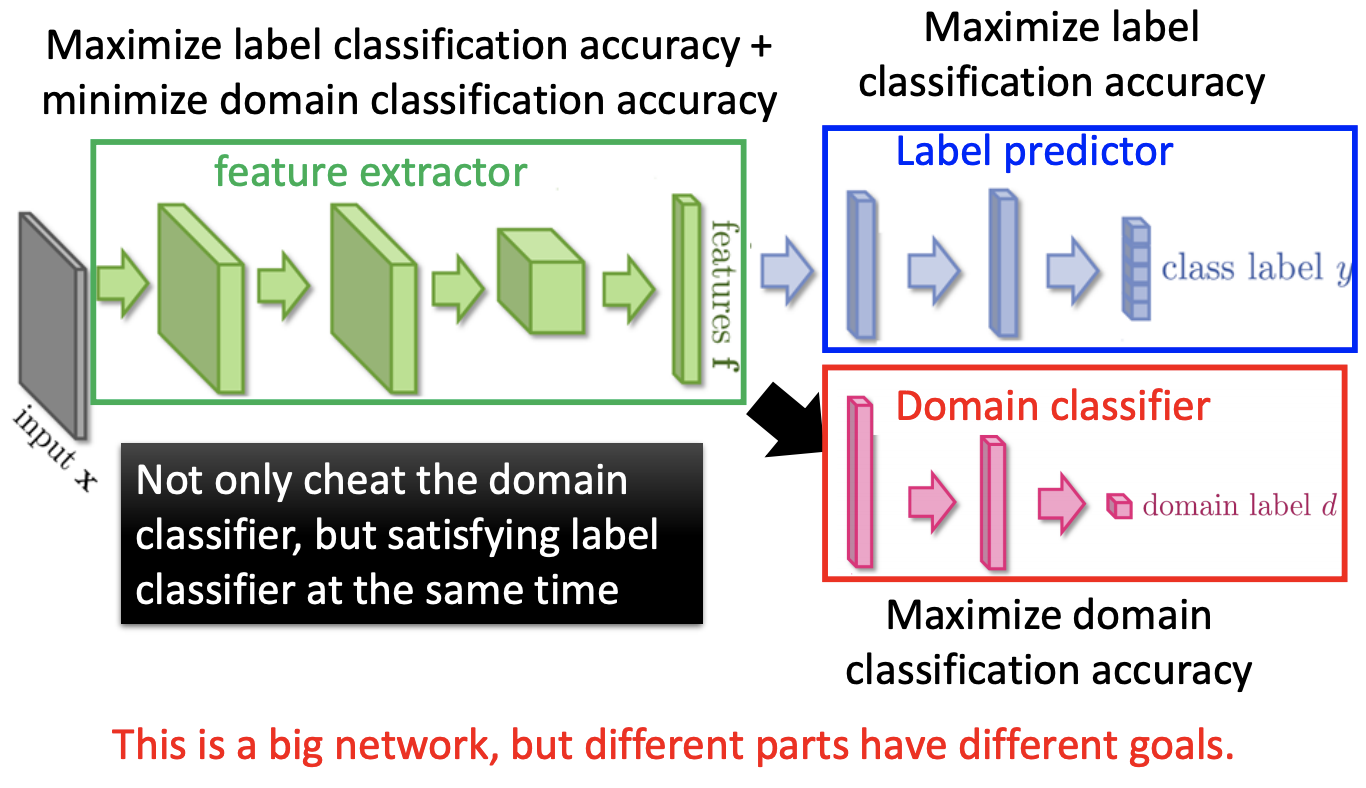
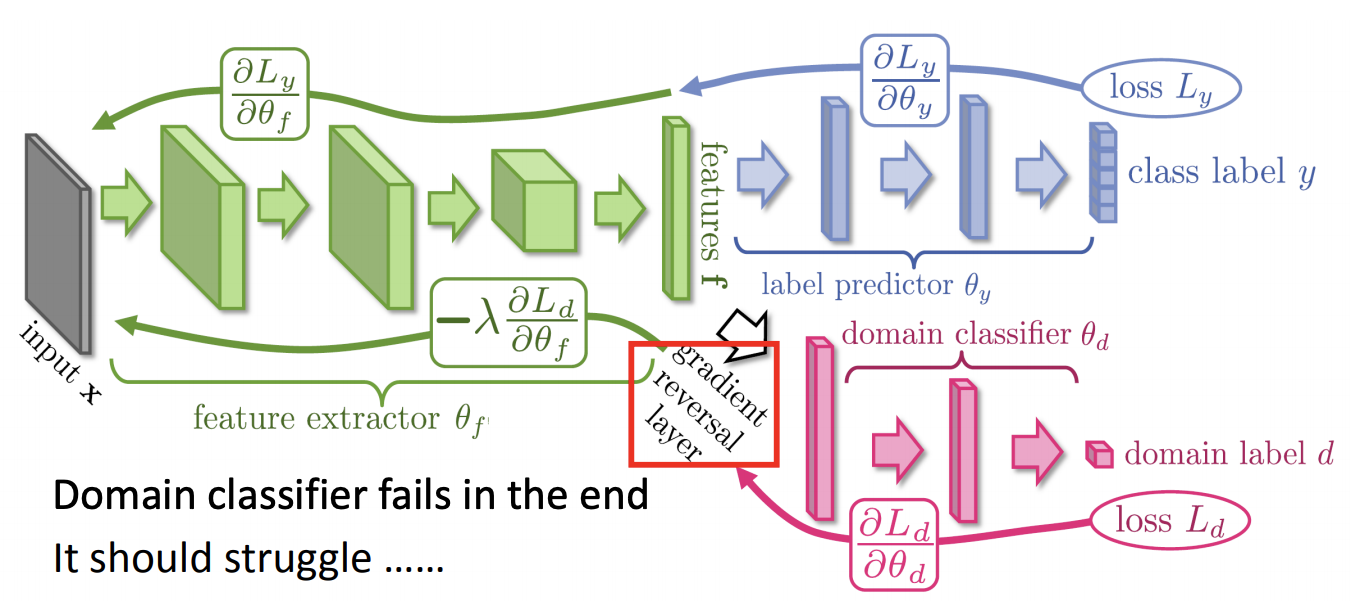
从上面的分析我们可以看出,直接将source data中的模型迁移到target data上主要存在的问题是,对于不同的背景,模型对于不同domain data的区分太明显了,即我们需要将彩色背景忽略,提取出与背景无关的数字特征,使得图中红色的点和蓝色的点都混在一起(这样便消除了背景颜色的影响)。
在上面的模型中,加入了Domian Classifier的部分,这部分的作用便是尽可能减小背景颜色影响。我们希望提取到features可以消除不同domain label的影响,所以domain classifier的任务可以正确区分不同的domain;但是只有这样一个模型也是不可以的,模型消除了彩色样本的同时还需要对辨识任务有作用,所以除了domain classifier之外,还需要一个label predictor,二者协同工作,domain classifier的目标是最小化classifier的accuracy,而label predictor的目标是最大化predictor的accuracy。右图则是其训练、参数更新的过程。六、Zero-shot learning
1、attribute embedding
对于Zero-shot learning来说,source data和target data上的任务是不同的。
Zero-shot learning主要思想是模型不是直接训练样本的label,而是将每一个class表示成一些属性。这样在预测的时候,我们可以通过看当前预测的样本和哪些样本的attribute比较类似。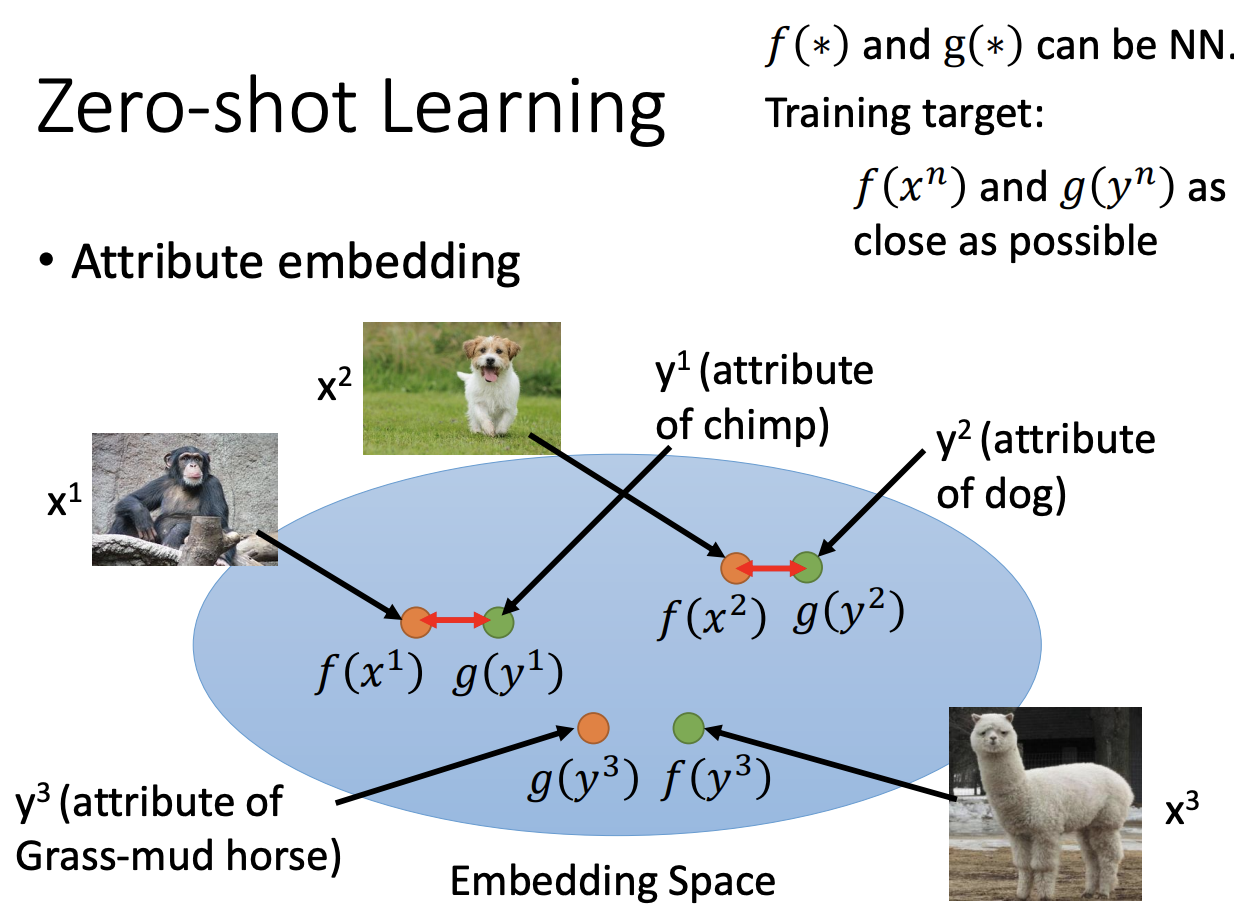
如上图所示,我们希望 f ( x n ) f(x^n) f(xn)与 g ( y n ) g(y^n) g(yn)更接近, x n x^n xn是真实的样本, y n y^n yn是提取到的 x n x^n xn的attribute。所以目标函数为:
f ∗ , g ∗ = arg min f , g ∑ n ∣ ∣ f ( x n ) − g ( y n ) ∣ ∣ 2 \begin{aligned} f^*,g^*=\mathop{\arg\min}_{f,g} \sum_n||f(x^n) - g(y^n)||_2 \end{aligned} f∗,g∗=argminf,gn∑∣∣f(xn)−g(yn)∣∣2
但是这样会存在什么问题呢?这样做会使得正样本之间的差距等于0,但是我们没有限制负样本。所以正确的损失函数应该是下面的式子:
f ∗ , g ∗ = arg min f , g ∑ n m a x ( 0 , k − f ( x n ) ⋅ g ( y n ) + m a x m ≠ n f ( x n ) ⋅ g ( y m ) ) \begin{aligned} f^*,g^*=\mathop{\arg\min}_{f,g} \sum_n max(0, k-f(x^n) \cdot g(y^n) + max_{m \neq n} f(x^n) \cdot g(y^m)) \end{aligned} f∗,g∗=argminf,gn∑max(0,k−f(xn)⋅g(yn)+maxm̸=nf(xn)⋅g(ym))
对于max()来讲当 k − f ( x n ) ⋅ g ( y n ) + m a x m ≠ n f ( x n ) ⋅ g ( y m ) < 0 k-f(x^n) \cdot g(y^n) + max_{m \neq n} f(x^n) \cdot g(y^m)<0 k−f(xn)⋅g(yn)+maxm̸=nf(xn)⋅g(ym)<0时损失为0。此时 f ( x n ) ⋅ g ( y n ) − m a x m ≠ n f ( x n ) ⋅ g ( y m ) > k f(x^n) \cdot g(y^n) - max_{m \neq n} f(x^n) \cdot g(y^m) > k f(xn)⋅g(yn)−maxm̸=nf(xn)⋅g(ym)>k,也就是说, f ( x n ) ⋅ g ( y n ) f(x^n) \cdot g(y^n) f(xn)⋅g(yn)的值要足够大, 且保证负样本之间的乘积足够小才可以。
2、semantic embedding
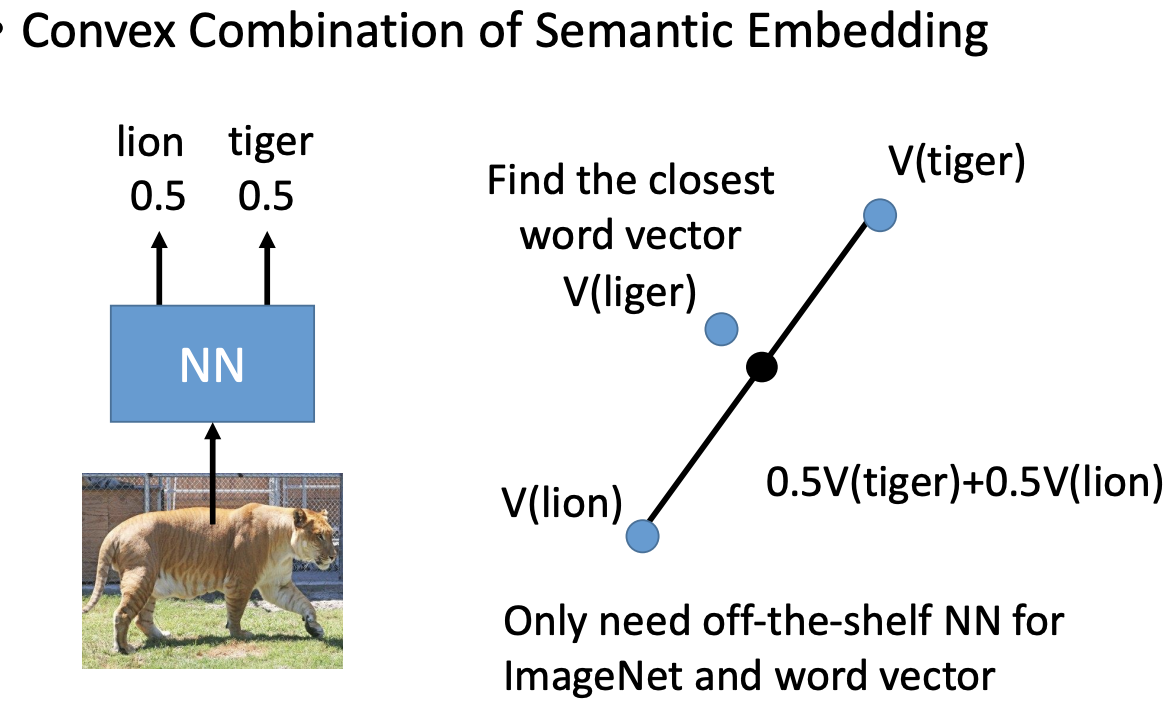
如上图所示,对于某一个动物,我们不能直接预测出其类别,但是可以预测出其与哪几个类别最为相似。如果你预测出来是lion和tiger的概率各0.5,则可以使用lion和tiger的向量分别乘以权重: α = 0.5 V ( l i o n ) + 0.5 V ( t i g e r ) \alpha = 0.5V(lion) + 0.5V(tiger) α=0.5V(lion)+0.5V(tiger),然后查看和 α \alpha α最相近的词语,把其当做最终的预测结果。当然除了使用NN训练之后,也可以使用word2vec等训练向量的表示。
转载地址:http://tagki.baihongyu.com/